
Der Einsatz von Cognitive Crash Dummies in der formalen Evaluation mit GOMS

Seit jeher beschäftigt sich die Human-Computer Interaction (HCI) unter anderem mit der Frage, wie menschliches Verhalten analysiert und berechnet werden kann. Im Zeitalter der Digitalisierung wird die Frage zunehmend immanenter. Wäre es daher nicht schön, im stressigen Projektalltag eines Konzeptionsprojektes eine Methode parat zu haben, mit der sich ‚lean‘ und ohne Einsatz von Probanden Aussagen über die Effizienz von Use Cases und deren UI-Varianten treffen lassen? In diesem Artikel stelle ich Ihnen die modellbasierte Evaluation mit Fokus auf GOMS vor (Goals, Operators, Methods and Selection Rules, Card et al. 1983), mit deren Hilfe es möglich ist, durch virtuelle Probanden, auch Cognitive Crash Dummys, die Effizienz von Schnittstellen bewerten zu lassen.
Cognitive Crash Dummies in GOMS
Das Szenario
Stellen Sie sich folgende völlig realistische Situation vor: Für eine neu zu entwickelnde Antragsstrecke einer Versicherung haben Sie mehrere Varianten von Use Cases erstellt, die unterschiedliche Eigenschaften des UI vorsehen. Bevor Sie in die Konzeption gehen möchten Sie nun zeitintensive Use Cases identifizieren und valide abschätzen, wie lange Nutzer bis zum Erreichen ihres Ziels benötigen. Ihr Prototyp ist aktuell jedoch so rudimentär (oder nicht existent), dass er für einen Usability-Test nicht geeignet ist. Hinzu kommt, dass die Projektressourcen sowieso sehr knapp sind, so dass ein Test der Schnittstelle nur mit wenigen Nutzern möglich wäre, was die Aussagekraft der erhobenen Task-Time weiter minimieren würde. Auf einen A/B-Test wollen und können Sie ebenso wenig warten (zu wenig Entwicklerzeit oder gar zu geringer Traffic um Signifikanzen zu messen).
Ideal wäre es doch entscheiden zu können, mit welchem Design der Nutzer bei geringem Aufwand schneller an sein Ziel kommt. So könnten Sie bestimmen, welches Design gar nicht funktioniert und handfeste Zahlen darüber ermitteln, welchen Fortschritt Sie im Vergleich zu einem Konkurrenz-Design machen.
Wenn wir ein Konzeptionsprojekt durchführen oder begleiten, ist die Optimierung der Effizienz bzw. Zeitersparnis eine wesentliche Eigenschaft guter Usability. Goldstandard in der HCI ist die Durchführung einer empirischen Evaluation mit einer angemessenen Nutzeranzahl, bei der wir verschiedene Metriken der Gebrauchstauglichkeit und Zufriedenstellung erfassen.
Um Aussagen über die Effektivität zu treffen, ist ebenso eine heuristische Evaluation (Expert Review, Cognitive Walkthrough) möglich, bei der die Bewertung auf Basis anerkannter heuristischer Methoden und des Domänen- bzw. Expertenwissens erfolgt. Daten zur Effizienz können hierbei jedoch nicht erhoben werden.
Des Rätsels Lösung: Die formale Evaluation und Cognitive Crash Dummies
Für das zu Beginn skizzierte Szenario kommen formale Evaluationsmethoden zur Messung der Effizienz in Betracht. Genutzt werden dabei sogenannte ‚Human Behaviour Models‘ auch ‚Cognitive Crash Dummies‘ (B. John 2014), also mathematische Modelle, mit deren Hilfe das Verhalten von Menschen simuliert werden kann. Diese können genutzt werden, um Annahmen darüber zu treffen, wie einfach und effizient Schnittstellen zu bedienen sind.
Leider werden diese Modelle recht stiefmütterlich behandelt und häufig als zu wissenschaftlich abgekanzelt. Dabei können sie die Lücke zwischen empirischer und heuristischer Evaluation recht gut füllen. Warum nun „zu wissenschaftlich“? In der Tat wurden seit den 1980er Jahren kognitive Architekturen entwickelt, mit deren Hilfe Annahmen über die Denk- und Handlungsabläufe des Menschen gemacht werden können (z. B. SOAR, ACT-R). Diese werden unter anderem in virtuellen Agenten (Billie, Alexa, Cortana, Watson etc.) eingesetzt um natürliche Entscheidungsmuster zu ermöglichen. Ein großes Problem dabei war und ist die fehlende Zugänglichkeit für den Projektalltag, welche durch Aspekte wie schwierige Berechnungen, aufwendiges Erstellen der Abläufe erschwert wird. Kurz gesagt liegt der Grund, warum die formale Evaluation so wenig Anwendung findet darin, dass sie von UX Designern und Entwicklern als zu schwer und umständlich zu erlernen wahrgenommen wird. Dabei bieten sie jedoch einige Vorteile bei der Optimierung von Bedienabläufen, welche den empirischen bzw. heuristischen Ansatz sinnvoll ergänzen könnten: „Using KLM you can predict a skilled user’s task time (error-free) to within 10-20% of the actual time. To put this amount of error in perspective, it would take testing 80 users to have the same margin of error as using KLM.“ (Sauro 2009)
GOMS-Modell
Das Grundmodell zur formalen Evaluation ist GOMS (Goals, Operators, Methods and Selection Rules, zu Deutsch: Ziele, Operatoren, Methoden und Selektionsregeln) und bezeichnet eine Familie mehrerer Modellierungs-Techniken. Grundlage ist das Nutzerverhalten auf die elementaren Aktionen zu reduzieren. Diese Aktionen werden dann in einem Modell dargestellt, um die Effizienz der Aktionen zu ermitteln.
Ein GOMS-Modell besteht folglich aus Methoden, welche genutzt werden, um Ziele zu erreichen. Eine Methode besteht aus einer Sequenz von Operatoren (Handlungsabläufen), welche der Nutzer ausführt, die auch Zwischen-Ziele beinhalten. Gibt es mehr als eine Methode, die angewandt werden kann, um ein Ziel zu erreichen, wird eine Selektionsregel angewandt um abhängig vom Kontext die geeignete Methode festzulegen. In der nachfolgenden Abbildung ist der Verlauf dargestellt.
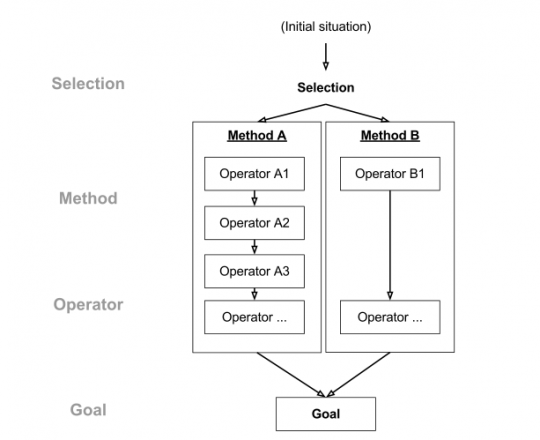
Abb. 1: Visualisierung des CMN-GOMS-Modells zur Analyse der Effizienz einer Aufgabensequenz in der CMN-GOMS-Methode (Wikipedia Commons Lizenz)
Seit deren Entwicklung 1983 wurde die Modellfamilie stetig erweitert. Einige Varianten sind:
- Die originale Card, Moran and Newell-GOMS-Methode (CMN-GOMS)
- Das einfache Keystroke Level Model (KLM-GOMS) welche die Interaktion am Computer mit Maus und Tastatur berücksichtigt
- Natural GOMS Language (NGOMSL) mit dem Annahmen über die Lernaktivität getroffen werden können
- Cognitive-Perceptual-Motor-GOMS (CPM-GOMS) ist die komplexeste Variante ermöglicht die Darstellung paralleler asynchroner Denk- und Handlungsabläufe (Multitasking); geht davon aus, dass kognitive Vorgänge in spezialisierten Prozessoren stattfinden (visueller Prozessor, motorischer Prozessor etc.)
- Touch Level Model (TLM) – Erweiterung von KLM um die Bediensequenzen über eine Touchoberfläche mobiler Endgeräte abzudecken
Dabei gibt es viele Anwendungsgebiete für GOMS. Einige davon sind nachfolgend aufgelistet:
- Ist in allen Phasen der Konzeption und Systementwicklung nutzbar (Neu-, Re-Design, Evaluierung, Wartung)
- Annahmen über Effizienz eines zukünftigen Designs, bevor Umsetzung startet
- Ermöglicht Vergleiche der Effizienz von verschiedenen Design-Varianten ohne fertigen Prototypen
- Kostensparend, da keine realen Probanden notwendig
- Ermöglicht Sichtbarmachung des gesamten prozeduralen Wissens und ermöglicht somit die Denkprozesse der Nutzer beim Bearbeiten von Aufgaben besser nachzuvollziehen
Keystroke-Level-Model anwenden
Am Beispiel des Keystroke Level Model möchte ich kurz beschreiben, welche Schritte notwendig sind, um eine KLM-GOMS-Analyse durchzuführen. KLM verwendet keine Ziele, Methoden oder Selektionsregeln wie CPM-GOMS, ist jedoch aufgrund der geringen Komplexität gut geeignet, um ein Verständnis für GOMS zu erhalten. Sie lässt sich in der simplen Formel zusammenfassen:
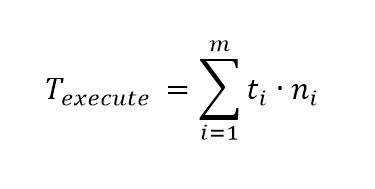
Abb. 2: Berechnung der Ausführungszeit im KLM-GOMS. Texecute = Ausführungszeit; t= Ausführungszeit einer Operation; n=Häufigkeit der Einzeloperation; i = Laufindex
Um eine KLM-GOMS-Analyse einer Schnittstelle durchzuführen, sind folgende Schritte notwendig:
-
- 1. Eine oder mehrere repräsentative Szenarien werden ausgewählt.
-
- 2. Design wird so weit spezifiziert, dass es möglich ist, die Keystroke-Level-Aktionen aufzulisten.
-
- 3. Auflisten der Keystroke-Level-Operatoren, die in der Aufgabe angewandt werden
-
- 4. Hinzufügen der Mental Operators (M) an spezifischen Stellen (M-Operatoren werden anhand von empirisch-validierten Heuristiken an den Stellen gesetzt, wo angenommen wird, dass erfahrene Nutzer pausieren oder Such-Aktionen und Denkprozesse durchführen).
-
- 5. Jedem Operator wird eine empirisch-verifizierte Durchführungszeit hinzugefügt.
-
- 6. Der Output ist die Zeit, die ein Nutzer benötigt, um eine Aufgabe mit dem entsprechenden System durchzuführen.
Einige zur Analyse notwendigen Operatoren mit Ausführungszeiten sind nachfolgend aufgelistet (übernommen aus Kieras 2001):
- K (keystroke) – 0,8 bis 1,2 Sek
- K (mouse) – 0,1 – 0,4 Sek
- P (point with mouse) – 1,10 Sek
- H (home hands between devices) – 0,40 Sek
- R (system response time) – Abhängig vom System
- M (mental operator) – 0,6 bis 1,35; im Durchschnitt 1,2 Sek
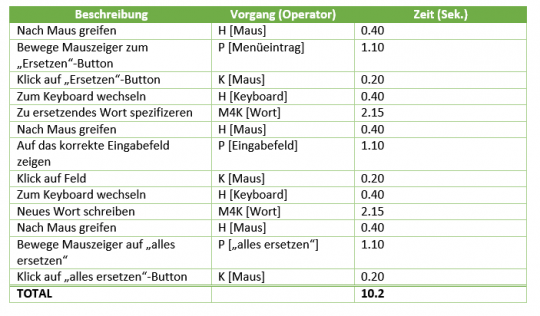
Abb. 3: Im nachfolgenden Bild ist beispielhaft dargestellt, wie viel Zeit das Ersetzen eines Wortes mit vier Buchstaben innerhalb eines Word-Dokumentes in Anspruch nimmt (10.2 Sek). Der M-Operator (M4K) ist hier zusammengefasst: mentale Vorbereitung, dann 4 Tastenschläge (nach Hochstein 2002).
Möchten Sie es selbst einmal ausprobieren? J. Sauro hat in einem Artikel zu KLM ein kleines Tool gebaut, mit dem KLM am Beispiel eines Vergleiches zwischen Drop-Down und Radio-Button-Auswahl getestet werden kann. Auch bietet das MIT einen einfachen Rechner an, mit dem schnell die Execution Time ermittelt werden kann.
In der kommenden Woche liefere ich Ihnen den zweiten Teil meines Artikels mit interessanten Tools für den praktischen Einsatz und weiterführende Links zum Thema der formalen Evaluation. Wenn Sie bereits Anmerkungen oder Fragen haben sollten, freue ich mich auf Ihr Feedback.
Endlich mal so erklärt, dass es auch „normale“ Menschen verstehen können! 🙂 Allein das Beispiel mit dem Keystroke Level Model ist sehr hilfreich und kann eigentlich direkt angewendet werden. Vielen Dank. 🙂